Otázka, zda je Generative Engine Optimization (GEO) samostatná disciplína, nebo jen marketingový návlek na klasické SEO, má velmi praktické dopady. Ovlivňuje rozpočty, strategie a způsob, jakým firmy připravují své weby na svět AI vyhledávání. Google ve svém nedávno zveřejněném návodu Optimizing your website for generative AI features on Google Search na ni odpovídá jednoznačně: „From Google Search’s perspective, optimizing for generative AI search is optimizing for the search experience, and thus still SEO.„[1] Tedy: žádné GEO, žádné AEO ani AI SEO, pořád jen staré dobré SEO. Návod zároveň radí ignorovat věci jako LLMs.txt, chunking obsahu, přepisování textů pro AI, strukturovaná data nebo honění se za neautentickými zmínkami. Z pohledu Google Search to vše dává smysl. Stojí ale za to se podívat, jestli to stanovisko obstojí mimo bublinu konzultantů SEO a Google.
V argumentech proti samostatnosti GEO se opakovaně objevují dvě tvrzení, které stojí za vyjasnění, protože jedno z nich má kořeny v historie a druhé pramení z technického nepochopení toho, jak AI systémy reálně fungují.
První tvrzení: „Google dominuje, tedy GEO = SEO pro Google“
Teze zní zhruba takto: Google je a bude dominantním dodavatelem informací, takže debata o GEO mimo Google je zbytečná, a ti, kteří se zaobírají GEO (jak obvykle zaznívá z komunity SEO konzultantů) jsou prodavači teplé vody, protože „GEO je jen SEO“. Zmiňovaný dokument od Google (odkazy na všechny zdroje najdete na konci článku), pak slouží jako velmi silný argument tohoto pohledu.
Faktem je, že posledních dvacet let to platilo. Google opravdu dominoval získávání informací online a SEO se svými technikami optimalizace pro vyhledávače byla pro on-line viditelnost docela zásadní marketingový kanál. Jenže chování uživatelů se reálně mění a data to potvrzují.
ChatGPT v únoru 2026 překročil 900 milionů týdenních aktivních uživatelů, což je více než dvojnásobek oproti 400 milionům ohlášeným v únoru 2025 [2][3]. Aplikace Gemini přesáhla v Q4 2025 hranici 750 milionů měsíčních aktivních uživatelů [4][5]. Současně sílí tlak na klasické vyhledávání – studie Ahrefs zopakovaná na datech z prosince 2025 ukázala 58% pokles CTR pro první pozici v SERPu při zobrazení AI Overview, oproti 34,5 % v dubnové verzi téhož měření [6][7]. Seer Interactive při analýze 3 119 informačních dotazů eviduje 49,4 % až 65,2 % propad organického CTR u dotazů s AIO [8]. Pew Research Center na vzorku 900 dospělých Američanů zaznamenal propad z 15 na 8 % prokliků na klasické výsledky tam, kde se objevila AI sumarizace; kliky na odkazy uvnitř sumarizace tvoří pouhé 1 % [9][10].
Lidé tedy chodí jinam – a i tam, kde zůstávají, kliky odcházejí do AI rozhraní. Argumentovat dnes „Google je dominantní, tedy GEO nemá smysl mimo SEO“ je věcně pravdivá premisa, ale bohužel s rychlou expirací. A je tu ještě další fakt: Google sám sebe kanibalizuje. Klasický SEO úspěch, tedy první pozice ve SERPu, dnes nese polovinu prokliků než před dvěma lety, právě kvůli AI Overviews. Pro firmy a jejich značky to znamená, že GEO není investice „kdyby náhodou“, ale příprava na exodus uživatelů, který už nastal.
Druhé tvrzení: „AI mě nezná, takže GEO nemá smysl“
Druhý názor je častější u netechnických marketingových specialistů a týká se způsobu, jak AI systémy reálně získávají informace. Typický scénář: někdo otevře ChatGPT, zeptá se „co víš o značce X“ a dostane zastaralou nebo nepřesnou odpověď. Z toho se vyvodí závěr „nemá smysl řešit GEO, AI o nás stejně neví“ nebo „dává staré a nepřesné informace“.
Tahle úvaha jednak přehlíží, jak moderní AI systémy reálně získávají informace a druhak ukazuje chyby v dosavadní on-line komunikaci firmy. A to se neslyší rádo.
Nejprve tedy k tomu, jak dnes většina chatovacích rozhraní velkých jazykových modelů, jako jsou ChatGPT, Perplexity, Claude, Copilot nebo Gemini, funguje. Při syntéze odpovědí používá tzv. RAG (retrieval-augmented generation). To znamená, že si sahá pro informace (data) do živého webu nebo do indexu některého z tradičních vyhledávačů. Když se uživatel zeptá na něco konkrétního nebo aktuálního, model nesestaví odpověď primárně z předtrénovaného korpusu. Spustí web search, zjistí, která stránka informace pravděpodobně obsahuje, případně si stáhne aktuální obsah a z toho generuje odpověď s citacemi.
Nejde tedy o to dostat se do trénovacích dat – v ovlivnitelném časovém rámci to ani jednoduše nelze, zejména u aktuálních a často se měnících dat to je v podstatě nemožné. Jde o to být citovatelným, autoritativním a strukturovaným zdrojem ve chvíli, kdy AI spustí retrieval. Hlavní předtrénovaný korpus znalostí je relevantní pro otázky typu „co je hlavní město Francie“, ne pro „kde v Ostravě najdu nejlepší restauraci“. A drtivá většina toho, co lidé v AI systémech reálně dělají, jsou právě komerční a aktuální dotazy. Otázka tedy nezní „zná mě AI z trénovacích dat“, ale „je můj obsah dostatečně dobře strukturovaný, citovatelný, konzistentní a aktuální, aby ho AI vybrala při retrievalu?“. To je trochu jiná disciplína než klasické SEO, byť se s ním v řadě bodů překrývá.
V debatě o GEO se kromě toho často zapomíná na jednu věc: Google je jen jeden z odpovědních systémů. ChatGPT, Perplexity, Claude, Gemini, Copilot – každý z nich má jiný retrieval, jiné zdroje, jiný způsob, jak vybírá citace, a jinou tržní pozici v daném regionu. Optimalizace, která nehraje roli pro Google, může u jiného systému znamenat rozdíl mezi citací a přeskočením, a naopak. Návod Googlu popisuje optimalizaci pro Google. Generalizovat ho na celý ekosystém AI vyhledávání není pochopení, ale zkreslení.
A teď budeme trochu polemizovat…
Dovolte mi se nyní na dokument podívat právě z hlediska GEO. V dokumentu se například dozvíte, že „Google systems are able to understand the nuance of multiple topics on a page and show the relevant piece to users.“ Z toho Google odvozuje, že chunking obsahu není potřeba.
Když se ale podíváme, co AI Overviews skutečně produkovaly hned od spuštění v květnu 2024 v podstatě až do dneška, vidíme jiný obrázek. Funkce uživatelům doporučovala přidávat netoxické lepidlo do pizzy, aby sýr lépe držel (zdrojem byl jedenáct let starý vtípek z Redditu). Doporučovala jíst aspoň jeden malý kámen denně, údajně podle „geologů z UC Berkeley“, což byl ve skutečnosti satirický článek z The Onion. Tvrdila, že hořící olej se hasí přidáním dalšího oleje, že Obama byl první muslimský prezident USA a že Andrew Johnson získal univerzitní tituly mezi roky 1947 a 2012, přestože zemřel v roce 1875 [11][12]. Když systém neumí rozlišit, že satirický článek o jezení kamenů není zdrojem výživových doporučení, je odvážné tvrdit, že rozumí jemným nuancím napříč mnoha tématy na jedné stránce.
Nemusíme chodit daleko. Dneska jsem třeba v jednom filmu slyšel slangové slovo „nargle“ – překladatelé se snažili ukázat „jiný slovník“ jedné z postav. Docela mne zajímalo, co to ty „nargle“ jsou. Brňáci odpustí, ale opravdu narozkám tak na Ostravsku neříkáme. Google, přestože bylo jak rozhraní v českém jazyce a i dotaz byl česky, preferoval anglický název kouzelných svtoření z Harryho Pottera (ano, ta otravná stvoření, kterým dali bratři Medkové krásné jméno „škrkna“).
…třeba o tom, co je pro RAG vhodnější
V úvodu dále Google popisuje, jak AI Overviews technicky fungují: RAG retrievuje konkrétní pasáže ze stránek a z nich generuje odpověď [1]. O pár odstavců níže pak tvrdí, že chunking obsahu není potřeba. Tady něco nesedí. Když retrieval pracuje s pasážemi a reranking je vybírá podle relevance k dotazu, je technicky samozřejmé, že tematicky čistá, dobře oddělená pasáž má vyšší šanci být vybraná jako citace než dlouhý odstavec, kde se prolíná pět témat. To vyplývá z toho, jak RAG technicky funguje. A praxe to potvrzuje: tematicky sevřené a dobře členěné stránky jsou v AI odpovědích citovány častěji než univerzální texty stylem „všechno o tématu X“. Jasně, chunking není povinnost. Ale tvrdit, že nehraje roli, když systém doslova retrievuje chunky, je v rozporu se samotným technickým popisem v úvodu téhož návodu.
…nebo o strukturovaných datech
„Structured data isn’t required for generative AI search, and there’s no special schema.org markup you need to add,“ je samozřejmě technicky pravda, protože AI systémy umí parsovat HTML a chápat synonyma. Funkčně je to ale silně zjednodušující.
RAG pipeline u AI systémů potřebuje fakta v jasné, neambivalentní formě. Strukturovaná data jsou nejlevnější způsob, jak je AI nabídnout. Schema.org markup pro Article, Product, FAQ, HowTo, Author, Organization, sameAs vazby na Wikidata a další knowledge bases, to vše AI systémy využívají při groundingu i při entitním rozpoznávání. Zda je „Apple“ v daném kontextu firma nebo ovoce, určuje entitní kontext často spolehlivěji než pouze přirozený text.
Existuje na to akademická opora. Princetonská práce Aggarwala a kolegů „GEO: Generative Engine Optimization“, prezentovaná na konferenci KDD ’24, sestavila benchmark GEO-bench s 10 000 dotazy z různých domén a měřila, jak konkrétní úpravy obsahu ovlivňují visibility v generativních odpovědích [13][14]. Tři nejúčinnější metody, tedy přidání zdrojů, citací a statistik, zvyšují visibility o 30 až 40 % na metrice Position-Adjusted Word Count. To není úplně marginální zlepšení. Signalizuje to, že způsob, jak je obsah strukturovaný a podložený, hraje v generativním retrievalu zásadní roli.
Google sám má knowledge graph postavený na strukturovaných datech. Microsoft Copilot dle vyjádření Microsoftu strukturovaná data přebírá z Bing indexu. Tvrzení, že Schema.org „není potřeba“, se proto z hlediska GEO chápe následovně: pro pouhou indexaci a zobrazení v rich results to není nustnost, ale pro maximalizaci pravděpodobnosti, že AI systém správně rozpozná, zařadí a cituje vaše informace, je to jeden z nejlepších poměrů cena/výkon, který dnes máte.
… a co brand mentions?
K brand mentions Google píše: „Seeking inauthentic ‚mentions‘ across the web isn’t as helpful as it might seem.“ S výhradou „inauthentic“ lze souhlasit, falešné zmínky AI může detekovat a ignorovat. Z praxe ale AI systémy citují a zmiňují značky podle source diversity, knowledge graph kontextu a tonality výskytu na renomovaných doménách. Placené spolupráce, PR, skrytá reklama nebo partnerské texty nejsou snadné odhalit, takže hranice mezi tím, co je „autentické“ a „neautentické“ je v reálu mnohem složitější rozpoznat, než návod Googlu naznačuje.
Analýza Ahrefs na vzorku 75 000 brandů zjistila korelaci 0,664 mezi brand mentions na webu a citation rate v AI odpovědích. Zhruba třikrát silnější vztah než u klasických zpětných odkazů (0,218), a co je důležité, mentions fungují i bez hyperlinku, pouze na základě výskytu jména značky v autoritativním kontextu [15]. Analýza Averi na 680 milionech citací ukazuje, že ChatGPT a Perplexity sdílejí pouze 11 % citovaných domén, podobně 12 % vychází i z nezávislé studie 15 000 dotazů napříč ChatGPT, Perplexity a Google AI [16]. Každá platforma má vlastní zdrojový pool a vlastní logiku výběru.
Citation rate v ChatGPT, Perplexity a AI Overviews potom silně koreluje s počtem a kvalitou autentických zmínek v autoritativních zdrojích, ať už to jsou branžová média, Wikipedia, odborné databáze, srovnávače, fóra jako Reddit nebo PR pokrytí. Konkrétní zdrojové preference jsou aktuálně docela úzké. ChatGPT cituje Wikipedii ve 47,9 % top citací, Perplexity cituje Reddit ve 46,7 % a Google AI Overviews výrazně preferuje YouTube s 23,3 % citačního podílu [17]. K tomu domény s aktivními profily na srovnávačích jako G2 nebo Capterra vykazují trojnásobně vyšší pravděpodobnost citace v ChatGPT než weby, které takovou přítomnost nemají [18]. Oba tyto weby podporují odměny za recenze. Stejně tak řada značek prokazatelně odměňuje své zákazníky (a nejen ty) za psaní „autentických“ recenzí. V klasickém SEO jednoduše nákup odkazů pro link juice v rámci linkbuildingu. V GEO získáváte zmínky pro entitní reputaci, často i bez odkazu, například pomocí placených článků.
Ke query fan-outu neboli rozkládání tématu na další Google popisuje, že model generuje paralelní příbuzné dotazy, tedy například „jak opravit trávník zaplevelený plevelem“ → „nejlepší herbicidy“, „odstranění plevele bez chemie“, „jak zabránit plevelu v trávníku“. Co to tedy znamená pro majitele webů? Opravu bude všeobjímající článek tím správným zdrojem, na základě něhož AI jasně rozdělí informací? Nebo je vhodnější ji rozsekat na jasné, pojmenované entitní čísti?
Je jasné, že pro viditelnost v tomto režimu je tedy rozumné pokrývat související podtémata. Současně ale Google v textu varuje před „scaled content abuse“, jinými slovy vytvářením separátních stránek pro každou variaci. Hranice mezi „legitimním pokrytím příbuzných queries“ a „spam scaled content“ je v návodu opět velice mlhavá a v praxi se odděluje zřejmě jen kvalitou a hloubkou zpracování. Pro GEO praktika to znamená pravidelnou kalibraci, kterou v klasickém SEO řešíte jiným způsobem. Zatímco tam jde primárně o pokrytí klíčových slov, v GEO o pokrytí entitního prostoru.
Jak věrohodné je oficiální Google sdělení?
Po několika technických rozporech stojí za zmínku ještě jedna otázka: nakolik se dá oficiálním Google sdělením věřit obecně.
V květnu 2024 se na GitHub omylem dostala interní dokumentace Google Search Content Warehouse API. Šlo o 2 596 modulů a 14 014 atributů, které popsali a analyzovali Rand Fishkin (SparkToro) a Mike King (iPullRank) [19][20][21]. Srovnání oficiálních sdělení Googlu s tím, co dokumentace skutečně popisuje, ukázalo řadu rozporů. John Mueller, Search Advocate v Googlu, dlouhodobě tvrdil, že Google nepoužívá Chrome browsing data pro účely rankingu. Dokumentace popisuje systém NavBoost, který využívá klikové signály a interakce uživatelů. Existenci NavBoost potvrdila i svědectví Pandu Nayaka v antimonopolním procesu DOJ vs. Google [19]. Gary Illyes označoval CTR a dwell time jako „generally made up crap“ a v uniklé dokumentaci se objevují atributy jako goodClicks, badClicks i lastLongestClicks. Googleři dlouhé roky popírali existenci „site authority“, sandboxu pro nové weby i samostatného hodnocení subdomén. Jak si na druhou stranu vysvětlit atributy siteAuthority i hostAge?
Autenticitu dokumentů potvrdili bývalí zaměstnanci Googlu. Google sám autenticitu nepopřel; pouze uvedl, že varuje před „nepřesnými předpoklady o Search založenými na vytržených, zastaralých nebo neúplných informacích“ [20]. Z pohledu Googlu to dává smysl, boj proti manipulacím (a co jiného SEO je…?) je jeho legitimní zájem. I za cenu ne vždy pravdivého popisu funkčních technik a lehké desinformace. Z pohledu praxe v SEO i GEO to ale znamená, že brát oficiální blog Googlu jako objektivní popis fungování Search nemá oporu. Validnější zdroje jsou kvantitativní studie, výzkum a experimenty z praxe.
Co Google v dokumentaci píše vs. co reálně provozuje
Stejný oficiální návod Googlu píše: „You don’t need to create new machine readable files, AI text files, markup, or Markdown to appear in generative AI search.“ Legrace je, že ten samý článek je ale veřejně dostupný i na URL https://developers.google.com/search/docs/fundamentals/ai-optimization-guide.md.txt s HTTP hlavičkou Content-Type: text/markdown; charset=utf-8 [26]. Tedy přesně to, co podle Google doporučení vlastně vůbec nepotřebujete, tedy strukturovanou, zhuštěnou, strojově čitelnou markdown verzi obsahu pro snadnější zpracování stroji a AI systémy. Zatímco HTML stránka je pro LLM plná šumu: CSS, JS, navigace, hlavičky, sidebary, cookie lišty, vedlejší prvky. Markdown verze je čistý obsah, snadno parsovatelný, levný na tokeny.
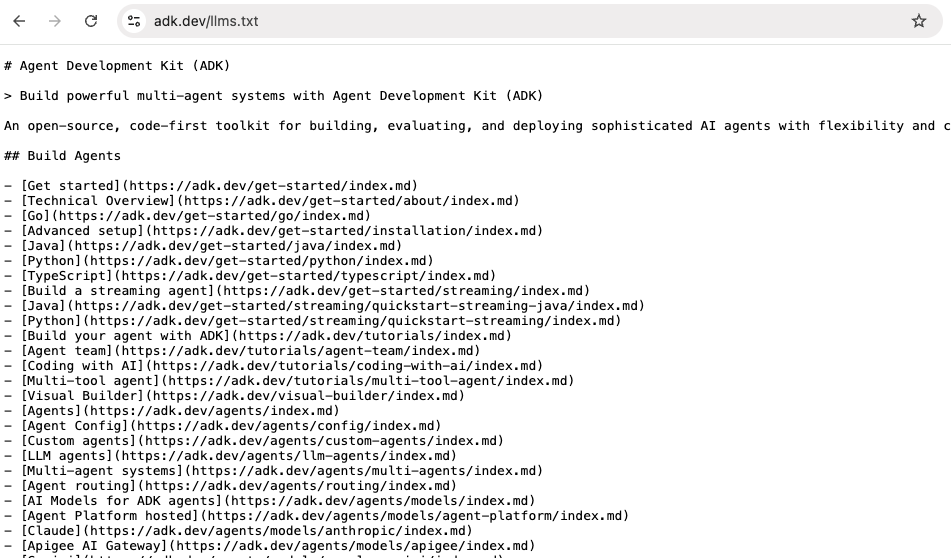
A není to ojedinělý případ. Google dodnes provozuje na svém projektu Agent Development Kit i klasický llms.txt soubor – tedy přesně ten formát, od jehož vytváření v dokumentaci odrazuje. Soubor na adk.dev/llms.txt obsahuje strukturovanou mapu dokumentace pro AI agenty a coding asistenty a Google sám doporučuje připojit ho přes MCP server [23]. Stejnou cestou jdou Anthropic, OpenAI, Perplexity, Stripe, Cloudflare a další technologičtí hráči.
TIP: Čtěte také Průvodce LLMs
Co tedy s llms.txt?
Empirická situace ohledně llms.txt je dnes celkem jednoznačná. Experiment OtterlyAI měřil 90 dní serverové logy: z 62 100 požadavků AI botů jich na llms.txt dorazilo pouhých 84, tedy 0,1 % [24]. John Mueller na Bluesky uvedl „FWIW no AI system currently uses llms.txt.“ a přirovnal jeho hodnotu k meta tagu keywords, tedy ke značce, kterou vyhledávače dávno ignorují, protože ji kontroluje vlastník webu [25]. Gary Illyes na Google Search Central Deep Dive 2025 potvrdil, že Google llms.txt nepodporuje a nehodlá podporovat [26]. Ahrefs ve své analýze shrnuje: žádný velký LLM provider llms.txt formálně nepřijal, neexistuje důkaz, že soubor zlepšuje retrieval, návštěvnost nebo přesnost modelů [24].
Kai Spriestersbach v rozboru „The llms.txt is dead. More precisely: a dud.“ [20] přidává ještě jeden důležitý a férový bod: existence llms.txt na dev docs Anthropic, OpenAI nebo Perplexity neznamená, že ClaudeBot, GPTBot nebo PerplexityBot čtou váš llms.txt při webovém retrievalu. To samé platí pro adk.dev/llms.txt od Googlu – jde o publishing pro vývojáře a coding asistenty, ne o důkaz, že systém čte llms.txt ostatních webů. Spriestersbach to trefně přirovnává: že má restaurace jídelní lístek, neznamená, že před vařením čte jídelní lístky jiných restaurací.
Tahle námitka je oprávněná a nelze ji obejít. Co z toho ale plyne pro spor o GEO?
Za prvé: akademický kvantitativní výzkum dopadu llms.txt na visibility v AI odpovědích zatím neexistuje. Co máme, jsou serverové logy a vyjádření zástupců providerů. To je silná indicie pro „dnes nehraje“, ale slabý důkaz pro „nikdy hrát nebude“. Standardy procházejí fází přijímání, nepřijímání, opětovného přijímání. Robots.txt potřeboval čas na adopci, Schema.org procházel obdobím skepse. Být brzkým adopterem v případě LLMs.txt stojí pár minut práce, riziko je nulové.
Za druhé, a to je pointa pro debatu o GEO: spor o llms.txt jako konkrétní formát nevyvrací nutnost GEO jako disciplíny. Spriestersbach v závěru sám doporučuje „what to do instead“: content quality and citability, semantic structuring, topical authority, monitoring AI visibility. Tohle všechno jsou aktivity, které se v klasickém SEO neměřily, neoptimalizovaly a neorganizovaly stejným způsobem.
Za třetí: to, že Google sám servíruje markdown verze své dokumentace na .md.txt URL a provozuje llms.txt na adk.dev, není náhoda. Strukturovaný, zhuštěný, strojově čitelný obsah pro AI systémy je trend, který velcí hráči následují bez ohledu na to, jestli formálně podporují konkrétní standard. Jestli se vítězný formát bude jmenovat llms.txt, llms-full.txt, .md.txt, .md nebo nějak jinak, je otázka, na kterou se dnes nedá odpovědět. Že tím směrem cesta vede, je jasné z toho, co provideři reálně dělají, ne z toho, co píší v dokumentaci pro ostatní.
GEO není převlek SEO. Cíl je jiný
Velká část metodiky se mezi SEO a GEO překrývá. Kvalitní obsah, technická čistota, autorita (EEAT), odborné zázemí, indexovatelnost, sémantika – to platilo, platí a bude platit. V tomhle má Google pravdu a nikdo soudný to nezpochybňuje.
Cíl je ale jiný.
SEO se snaží dostat uživatele na web. Úspěchem je proklik, návštěva, konverze. Klíčové metriky jsou organic traffic, pozice ve SERPu, CTR ze SERPu. GEO chce dostat značku, produkt nebo informaci do odpovědi, kterou si uživatel přečte rovnou v AI rozhraní, ideálně se zachováním pravdivosti, konzistence a s co největší mírou kontroly nad tím, co o značce AI říká. Úspěchem je zmínka, citace, doporučení, share of voice v AI odpovědích, a často bez okamžitého kliknutí na web.
Jiný cíl, jiné metriky, jiná taktika. Kdo měřil návštěvnost z AI Overviews nebo z ChatGPT search, ví, že kliky už nejsou jedinou metrikou. Důležité je o tom být v odpovědi, být citovanou autoritou, nebýt přeskočen a ovlivnit, jak AI o značce mluví. To se měří a optimalizuje jinak než pozice v SERPu.
Citovaní skeptici llms.txt (Spriestersbach, Ahrefs) v doporučeních „co dělat místo toho“ popisují přesně ty disciplíny, které pod GEO patří: citability, semantic structuring, topical authority, AI visibility monitoring. Spor je tak víc o názvosloví než o podstatu věci. Můžeme tomu říkat AI SEO, GEO, AEO, LLMO a na názvu popravdě nezáleží. Ale tvářit se, že je to úplně totéž jako klasické SEO, je podobně silné jako tvrdit, že content marketing je jen copywriting. Část metodiky se překrývá, cíl ale není stejný.
Závěr
Podle Googlu je GEO jen SEO. Tvrdí to, protože z jeho pohledu je to pravda – z hlediska Google Search to optimalizace pro vyhledávací zážitek pořád je. A z hlediska Googlu je i logicky výhodnější tvrdit, že žádné nové discipliny netřeba, žádné nové soubory netřeba, dělejte to, co děláte celé roky.
Google ale není jediný systém. Halucinace AI Overviews ukazují, že porozumění nuancím má dost vážné limity. RAG paradox v jeho vlastním návodu ukazuje, že chunking technicky hraje roli, i když to text později popírá. Princetonský výzkum kvantifikuje, že úpravy obsahu pro generativní enginy přinášejí 30 až 40 procent visibility liftu. Leak interní dokumentace z roku 2024 ukazuje, že brát oficiální Google sdělení jako objektivní pravdu o fungování Search nemá oporu. A to, že Google sám servíruje markdown verzi své dokumentace o tom, že markdown verze nepotřebujete, a souběžně provozuje llms.txt na adk.dev, je názorný důkaz, že realita je složitější, než PR text naznačuje.
Co se llms.txt jako konkrétního formátu týče, empirická data zatím mluví dost jasně: aktuálně ho velké AI systémy nečtou. Akademický kvantitativní výzkum dopadu na visibility v AI odpovědích zatím chybí a teprve ukáže, kam se to celé vyvine. Tahle dílčí otázka ale není to hlavní. Hlavní je, že rozdíl mezi SEO a GEO není v tom, jestli vytvoříte jeden konkrétní textový soubor, ale v tom, jaké cíle si stavíte a jak měříte úspěch. Stejné otázky, jaké si přede dvaceti lety pokládalo formující se SEO, si dnes pokládá GEO. Některé odpovědi se v čase ukáží jako slepé uličky, jiné jako nové standardy. To je normální fáze vývoje disciplíny – ne argument pro to, že disciplína sama neexistuje nebo nefunguje.
Zdroje
- [1] Google Search Central. Optimizing your website for generative AI features on Google Search. https://developers.google.com/search/docs/fundamentals/ai-optimization-guide
- [2] DemandSage. ChatGPT Statistics (2026) – Active Users & Growth Data. Březen 2026. https://www.demandsage.com/chatgpt-statistics/
- [3] Reuters / TechCrunch. Sam Altman says ChatGPT has hit 800M weekly active users. Říjen 2025. https://techcrunch.com/2025/10/06/sam-altman-says-chatgpt-has-hit-800m-weekly-active-users/
- [4] TechCrunch. Google’s Gemini app has surpassed 750M monthly active users. 4. února 2026. https://techcrunch.com/2026/02/04/googles-gemini-app-has-surpassed-750m-monthly-active-users/
- [5] Alphabet Q4 2025 Earnings Report. Únor 2026.
- [6] Ahrefs (Ryan Law, Xibeijia Guan). Update: AI Overviews Reduce Clicks by 58%. Únor 2026. https://ahrefs.com/blog/ai-overviews-reduce-clicks-update/
- [7] Ahrefs (Ryan Law). AI Overviews Reduce Clicks by 34.5%. Duben 2025. https://ahrefs.com/blog/ai-overviews-reduce-clicks/
- [8] Seer Interactive. AIO Impact on Google CTR: September 2025 Update. Listopad 2025. https://www.seerinteractive.com/insights/aio-impact-on-google-ctr-september-2025-update
- [9] Pew Research Center (Athena Chapekis, Anna Lieb). Google users are less likely to click on links when an AI summary appears in the results. 22. července 2025. https://www.pewresearch.org/short-reads/2025/07/22/google-users-are-less-likely-to-click-on-links-when-an-ai-summary-appears-in-the-results/
- [10] Search Engine Land. Google’s AI Overviews are hurting clicks: Pew study. Červenec 2025. https://searchengineland.com/google-ai-overviews-hurting-clicks-study-459434
- [11] MIT Technology Review (Rhiannon Williams). Why Google’s AI Overviews gets things wrong. 31. května 2024. https://www.technologyreview.com/2024/05/31/1093019/why-are-googles-ai-overviews-results-so-bad/
- [12] ACS Information Age. Google goes viral after AI says to put glue on pizza, eat rocks. Květen 2024. https://ia.acs.org.au/article/2024/google-goes-viral-after-ai-says-to-put-glue-on-pizza-eat-rocks.html
- [13] Aggarwal, P., Murahari, V., Rajpurohit, T., Kalyan, A., Narasimhan, K., Deshpande, A. GEO: Generative Engine Optimization. KDD ’24 – Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024. https://dl.acm.org/doi/10.1145/3637528.3671900
- [14] arXiv preprint 2311.09735 – GEO: Generative Engine Optimization. https://arxiv.org/abs/2311.09735
- [15] Ahrefs. Brand mentions correlate with AI citation rates (r = 0,664) – analýza 75 000 brandů. 2026. Shrnutí: https://authoritytech.io/curated/ai-citation-11-percent-platform-overlap-per-engine-audit-2026
- [16] Averi. ChatGPT vs. Perplexity vs. Google AI Mode: The B2B SaaS Citation Benchmarks Report (2026). Analýza 680 milionů citací, 11% překryv mezi ChatGPT a Perplexity. https://www.averi.ai/how-to/chatgpt-vs.-perplexity-vs.-google-ai-mode-the-b2b-saas-citation-benchmarks-report-(2026)
- [17] Discovered Labs. AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources. ChatGPT cituje Wikipedii ve 47,9 % top citací, Perplexity Reddit ve 46,7 %. Prosinec 2025. https://discoveredlabs.com/blog/ai-citation-patterns-how-chatgpt-claude-and-perplexity-choose-sources
- [18] Leapd Blog. How ChatGPT, Google AI Overviews, and Perplexity Source Information in 2026. Domény s profily na G2/Capterra mají 3× vyšší pravděpodobnost citace v ChatGPT. https://www.leapd.ai/blog/ai-visibility/how-chatgpt-google-ai-overviews-and-perplexity-source-information-in-2026
- [19] Mike King (iPullRank). Secrets from the Algorithm: Google Search’s Internal Engineering Documentation Has Leaked. 27. května 2024. https://ipullrank.com/google-algo-leak
- [20] Rand Fishkin (SparkToro). An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them. 27. května 2024. https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
- [21] Search Engine Land. HUGE Google Search document leak reveals inner workings of ranking algorithm. Květen 2024. https://searchengineland.com/google-search-document-leak-ranking-442617
- [22] Google Search Central. Optimizing your website for generative AI features on Google Search – markdown verze. https://developers.google.com/search/docs/fundamentals/ai-optimization-guide.md.txt (Content-Type: text/markdown; charset=utf-8)
- [23] Google Agent Development Kit. Coding with AI – konfigurace MCP serveru pro https://adk.dev/llms.txt. https://google.github.io/adk-docs/tutorials/coding-with-ai/
- [24] Kai Spriestersbach. The llms.txt is dead. More precisely: a dud. Medium, únor 2026. Cituje 90denní experiment OtterlyAI (62 100 botových požadavků, 84 na llms.txt, 0,1 %). https://medium.com/@kaispriestersbach/the-llms-txt-is-dead-more-precisely-a-dud-ab7bee4f469c
- [25] John Mueller (Google), Bluesky, 17. června 2025. „FWIW no AI system currently uses llms.txt.“ https://bsky.app/profile/johnmu.com – přehled diskuse: Search Engine Roundtable, https://www.seroundtable.com/google-ai-llms-txt-39607.html
- [26] Gary Illyes (Google), Google Search Central Deep Dive 2025. Diskuse shrnuta v: Is llms.txt Dead? The Current State of Adoption in 2025. https://llms-txt.io/blog/is-llms-txt-dead