
Stačí jeden úspěšný pokus a člověk uvěří, že jazykový model umí počítat. Pak nahrajete tabulku s tržbami za poslední měsíc, ChatGPT vám odpoví plynule, sebejistě, s pěkně naformátovanou odpovědí. A možná bude součet je špatně. Ne o hodně, o pár procent, tak akorát, aby si toho nikdo nevšiml, dokud to nezkontroluje v přes vzoreček Excelu. Tenhle scénář se v praxi opakuje pořád dokola a stojí za ním jeden rozšířený mýtus: že model, který tak dobře rozumí textu, musí přece stejně dobře rozumět i číslům, která v tom textu jsou.
Nerozumí. Ne když má počítat sám, tokenem po tokenu, přímo „z hlavy“. Tohle upřesnění je důležité hned na začátku, protože se k němu na konci vrátím: autor netvrdí, že se máte v případě jazykových modelů číslům úplně vyhýbat, ale že se nemáte nechat uchlácholit odhadem z jazykového vzoru. Řešení je jednoduché a bude to hlavní věc, kterou si odnesete, pokud dočtete článek do konce. Než se k němu ale dostaneme, pojďme se podívat, proč k té chybě vlastně dochází. Důvod je zajímavější, než se na první pohled zdá.
Čísla převedené na číselné identifikátory – tokeny
Jazykový model nikdy nevidí text tak, jak ho vidíte vy. Než se cokoliv dostane dovnitř sítě, projde tzv. tokenizací, což je proces, který rozseká vstup na menší kousky, takzvané tokeny, a každému přiřadí číselné ID ze slovníku modelu. U slov je to celkem intuitivní, ale u čísel to začne skřípat. Čísla totiž model převádí na číselné identifikátory (ID).
Číslo „12345“ se může rozpadnout na tokeny „123“ a „45“, zatímco „1 2345″ nebo „12,345″ se rozseká úplně jinak, přestože jde o stejnou hodnotu napsanou s mezerou nebo čárkou navíc. Různé tokenizéry řežou čísla po jedné, dvou nebo třech číslicích, a to, jak přesně se dané číslo rozpadne, závisí na tom, jestli stojí samo, s mezerou, s desetinnou čárkou nebo jako součást delšího řetězce. Výzkumníci Singh a Strouse (2024) přímo porovnali přístupy jednotlivých rodin modelů: GPT-3.5 a GPT-4 mají samostatné tokeny pro jedno-, dvou- a trojciferná čísla a delší čísla řežou zleva po trojicích, zatímco LLaMA a PaLM tokenizují každou číslici zvlášť, a prokázali, že právě tahle volba měřitelně ovlivňuje přesnost modelu v aritmetických úlohách.
Důsledek je docela zásadní: model nemá zaručeno, že pozná, že „742″, „0742″ a „742,00″ je tatáž hodnota. Pro člověka je to triviální ekvivalence, pro model je to otázka, jestli se tahle konkrétní kombinace tokenů dostatečně podobala něčemu, co viděl při tréninku. Aritmetika přitom vyžaduje naprostou konzistenci reprezentace – pokud ji nemáte, nepočítáte, jenom odhadujete.
Abych to nenechal jen v rovině tvrzení, stačí si to ověřit v tokenizeru přímo od OpenAI na platform.openai.com/tokenizer. Do pole jsem zadal pět zápisů, které člověk bez váhání přečte jako stejnou hodnotu: „742“, „742.0“, „0742“, „00742“ a „0000742.00“ – tedy číslo 742 samotné, s desetinnou tečkou a s různým počtem nul navíc vpředu.
Řetězec má dohromady jednatřicet znaků a tenhle konkrétní tokenizer z něj udělal sedmnáct tokenů, tedy skoro dva tokeny na každý zápis, a rozhodně ne jeden konzistentní token pro „toto je číslo 742“, který by se opakoval pětkrát. U jiné rodiny modelů nebo starší verze tokenizeru vyjde jiné konkrétní číslo, ale princip – že stejná hodnota v různém zápisu dostane různý počet a různé typy tokenů – zůstává stejný a dá se ověřit na kterémkoli z nich.
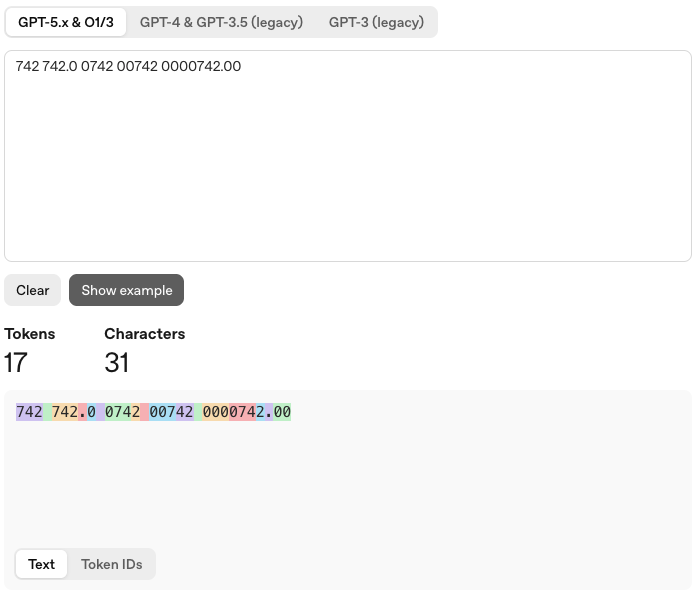
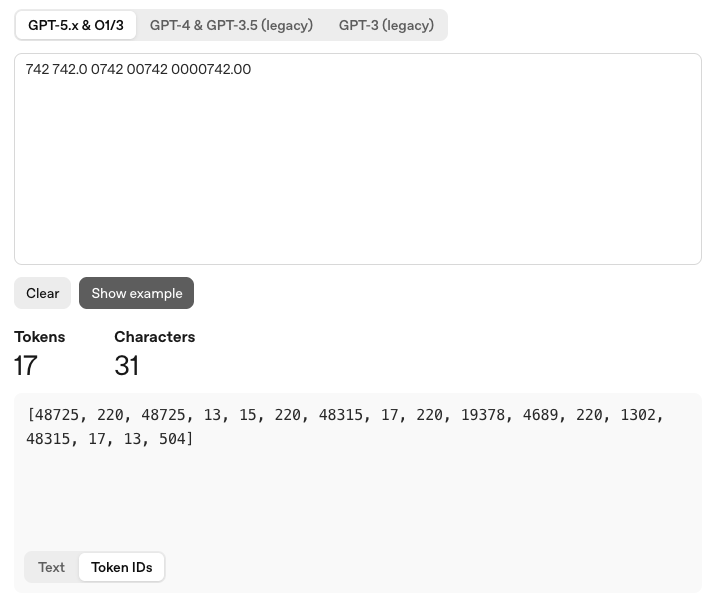
Zajímavé je, že stejné ID tokenu se objeví jen tam, kde je i řetězec znaků naprosto identický – token pro samostatné „742“ na začátku se znovu použije uvnitř „742.0“, protože tam je „742“ jako přesná shoda. Jakmile ale před číslo přibude jedna nebo dvě nuly navíc, tokenizer to rozseká úplně jinak a přiřadí úplně jiná ID, přestože numericky jde pořád o stejnou hodnotu se stejným počtem platných číslic. Tokenizace se tedy neřídí tím, co číslo znamená, ale tím, jaký přesný řetězec znaků už viděla a zná ze svého slovníku.
Vektorizace: proč embedding ≠ číselná osa
Tady se dostáváme k jádru věci, které většina lidí netuší. Poté, co se text rozseká na tokeny, každý token se převede na vektor ve vysokodimenzionálním prostoru. Tomuhle kroku se říká embedding, česky vektorizace. Klíčová otázka zní: co přesně tenhle vektor reprezentuje na samotném vstupu do sítě? Odpověď je, že to není přímo matematická hodnota čísla na číselné ose, ale statistický a sémantický kontext, ve kterém se daný token v trénovacích datech objevoval.
Jednoduše řečeno, na úrovni vstupního embeddingu nejsou „742“ a „743“ blízko sebe proto, že se liší o jedno číslo – jsou si blízké nebo vzdálené podle toho, jak podobně nebo nepodobně se v textech vyskytovaly. Číslo „742“ se možná objevovalo hlavně v kontextu poštovních směrovacích čísel, zatímco „743“ v úplně jiných situacích, a model si je pak v tomhle prvotním prostoru embeddingů umístí daleko od sebe, přestože matematicky jsou blízcí sousedi.
TTo ale neznamená, že model nemá o velikosti čísel žádné povědomí. Kadlčík a kol. (2025) ukázali, že už samotné embeddingy číselných tokenů v předtrénovaných jazykových modelech často obsahují velmi přesnou informaci o numerické hodnotě. Tato informace však nemusí být uspořádána lineárně; autoři tvrdí, že má často sinusoidální/Fourierovskou strukturu. Když se použije sonda s odpovídající induktivní předpojatostí, lze hodnotu čísla z embeddingu dekódovat s vysokou až téměř perfektní přesností. Starší jednodušší sondy, zejména lineární nebo běžné regresní, tuto strukturu nezachytily a mohly proto vyvolávat dojem, že numerické reprezentace modelů jsou mnohem méně přesné, než ve skutečnosti jsou.
Teoretické odůvodnění, proč se podobné struktury vůbec objevují, nabízí předcházející práce autorů Jiang a kol. (2024): strukturované reprezentace pojmů nejsou vázané na konkrétní architekturu, ale vznikají přirozeně jako důsledek toho, jak se síť během učení přizpůsobuje pravděpodobnostem v datech. Informace o velikosti čísla v modelu tedy skutečně je, nicméně je to naučený, odvozený vzorec, ke kterému je potřeba se prokousat speciální metodou, není to přímá aritmetická operace, na kterou se model při běžném generování odpovědi spolehlivě a vždy stejně napojí. Tahle nespolehlivost přístupu k vlastní znalosti je to, co při agregaci přes desítky nebo stovky hodnot přináší nepřesné odpovědi.
Chybějící fáze čištění dat
To, co se děje uvnitř tokenizace a embeddingu, se dá pojmenovat i jinak, praktičtěji: přes to, co v klasickém zpracování dat děláte vy sami, dřív než cokoliv vůbec spočítáte. V Pythonu s pandas, v SQL databázi nebo v Excelu existuje vždycky explicitní a povinná fáze čištění dat, která předchází jakémukoliv výpočtu a práci s daty. Deterministická funkce jako SUM nebo AVERAGE nemá žádnou toleranci k nejednotnosti. Dostane-li v jednom sloupečku hodnotu „742″, „0742″, „742.00″ nebo „742 Kč“, musí se to napřed převést na jeden jednoznačný typ, např. na float 742,0, jinak funkce spadne na chybě nebo vrátí nesmysl.
Proto datový analytik často stráví víc času čištěním a normalizací dat než samotnou analýzou. Od parsování formátů, sjednocení oddělovačů (nešťastný rozdíl tečka vs čárka v desetinných hodnotách), odstraněním měnových symbolů až po ošetření chybějících hodnot. Přesné číslo se v jednotlivých průzkumech liší, nicméně podle přehledu firmy Amperity (2026), který shrnuje několik takových průzkumů, uváděl CrowdFlower až 60 % času na čištění a organizaci dat, zatímco novější průzkum Anaconda mluví o zhruba 45 % na přípravu dat celkově. Všechny se ale shodují na tom, že příprava dat je jednoznačně největší časovou položkou v práci datového analytika, výrazně větší než samotné modelování nebo analýza. Tahle fáze není volitelná, je to podmínka, aby výpočet vůbec mohl proběhnout korektně.
U jazykového modelu tahle vynucená fáze jednoduše běžně neexistuje. Model nedostane příkaz „„“napřed sjednoť formát, pak počítej“ – prostě tokenizuje text tak, jak přišel, se všemi nekonzistencemi uvnitř. Místo explicitního čištění tam funguje jen naučená statistická aproximace, model se snaží odhadnout, že si jsou tyhle zápisy podobné, ale nemá to zaručeno, natož garantováno jako u přetypování v kódu. To, co je v klasickém zpracování dat samostatná, nutná a viditelná disciplína, model jen tiše obchází pravděpodobnostním hádáním.
Attention a jev lost in the middle
Druhý velký problém se objevuje ve chvíli, kdy dat není pár desítek, ale stovky řádků, a vejdou se celé do kontextového okna. Zdálo by se, že to je výhra, vždyť model má „všechno k dispozici“ najednou. Realita je jiná a souvisí s tím, jak funguje mechanismus pozornosti, attention, který určuje, které části vstupu model bere v potaz při generování další odpovědi.
V transformerové architektuře platí, že každý token se při zpracování dívá na všechny tokeny před sebou. Tomu se říká kauzální maskování. To má vedlejší efekt: tokeny na začátku sekvence jsou „viděné“ úplně všemi tokeny, které přijdou po nich, takže skrz síť jimi protéká víc informačního toku než tokeny uprostřed. Tokeny na konci zase těží z toho, že jsou nejblíž k místu, kde model generuje odpověď. Tahle kombinace vytváří tendenci, které výzkumníci říkají „lost in the middle“. Model má sklon věnovat spolehlivější pozornost začátku a konci vstupu, zatímco prostřední část bývá zpracovaná hůř.
Tenhle jev systematicky zdokumentovali autoři Liu a kol. (2024) z týmu na Stanfordu a Berkeley, kdy na úlohách typu vyhledávání v dlouhém kontextu ukázali, že přesnost modelu je nejvyšší, jestliže je relevantní informace na začátku nebo na konci vstupu, a klesá, když se nachází uprostřed. Vlastně docela podobně, jako vnímá člověk – slova na začátku přednášky a na konci vám utkví v hlavě víc než to uprostřed.
Je ale fér dodat, že jde o tendenci, ne o neměnnou vlastnost: novější replikační studie z roku 2026 ukazují, že síla efektu se mezi modely a datasety dost liší a ne vždy se dá stejně snadno zopakovat, takže v konkrétním modelu a konkrétní úloze může vyjít slaběji nebo silněji, než původní studie naznačuje.
Pro praktické použití to nicméně stále znamená, že když do modelu nahrajete tabulku se sto řádky a zeptáte se na součet, průměr nebo hledání odchylky, model si pravděpodobně spolehlivěji všimne prvních a posledních pár řádků, ale řádek čtyřicet sedm, kde se skrývá klíčová anomálie, má o něco vyšší riziko, že propadne sítí. Ne proto, že by byl model hloupý, ale proto, že architektura k tomuhle chování tíhne, i když v různé míře podle konkrétního modelu.
Halucinace a falešná jistota
Třetí a nejzákeřnější problém je to, jak model prezentuje výsledek. Na rozdíl od SQL dotazu nebo Excel vzorce, kde chybu poznáte podle chybové hlášky nebo zjevně nesmyslného čísla, model vyprodukuje odpověď ve stejném sebejistém, plynulém a strukturovaném tónu bez ohledu na to, jestli číslo skutečně odpovídá realitě nebo si ho model prostě domyslel. Neexistuje tam nic jako skóre spolehlivosti, žádné “ s tím si nejsem jistý“, žádná chybová hláška. Odhad a spočítaná hodnota vypadají navenek úplně stejně. Halucinace zní stejně jako správná odpověď.
Vysvětlení, proč se to tak děje, dala práce autorů Kalai a kol. (2025) z OpenAI. Podle nich modely nehádají z nedostatku inteligence, ale proto, že standardní tréninkové a evaluační postupy odměňují sebejisté odpovědi a trestají přiznání nejistoty, takže se modelu statisticky vyplatí naučit se hádat s přesvědčením místo toho, aby řekl „nevím“.
To je z pohledu výsledků nebezpečnější než klasická chyba, protože ta se dá zkontrolovat a dohledat. Vidíte vzorec, vidíte krok za krokem, jak se k číslu došlo. U jazykového modelu žádná taková dohledatelnost neexistuje.
Nedeterminismus aneb pokaždé jinak
Se sebejistotou souvisí ještě jedna vlastnost, na kterou se často zapomíná. Generování textu je založené na pravděpodobnostním vzorkování dalšího tokenu, ne na deterministickém výpočtu. To znamená, že stejný dotaz nad úplně stejnými daty může při dvou různých spuštěních dát mírně odlišný výsledek. Pro cokoliv, co má být opakovatelné a auditovatelné (měsíční report, daňový výpočet, porovnání meziročního růstu) je tohle zásadní problém. Deterministická funkce vrátí pokaždé identický výsledek. Jazykový model vám může dvakrát za sebou dát dvě různá čísla a obě budou znít stejně přesvědčivě.
Anthropic ve své dokumentaci k API přiznává, že ani při parametru temperature nastaveném na 0 výsledky nebudou zcela deterministické, a podobně to popisuje i OpenAI. Nezávislý benchmark platformy QAnswer (2026) tuhle nespolehlivost přímo změřil: opakované zadání stejného delšího promptu při teplotě 0 vedlo u některých modelů k identické odpovědi jen ve zlomku běhů, protože do hry vstupují i faktory mimo samotné vzorkování, jako je zaokrouhlování v plovoucí řádové čárce nebo způsob, jakým se požadavky dávkují na serveru.
Iluze pochopení
Poslední část problému je spíš psychologická než technická. Protože je výstup modelu plynulý, gramaticky správný a strukturovaný jako odpověď od kompetentního analytika, čtenář automaticky předpokládá, že model skutečně „prošel“ všechna data a spočítal je. Plynulost textu se v hlavě uživatele zaměňuje za správnost výpočtu, což je přesně ten typ kognitivní zkratky, kterou zkoumá behaviorální ekonomie. Pamatujete na maturitní zkoušky? Co vám radili spolužáci? Mluv, mluv, mluv. Když se zadrhneš, všichni poznají, že nevíš.
I tuto vlastnost již výzkumníci pojmenovali a říkají jí zpracovatelská plynulost (processing fluency). Alter a Oppenheimer (2009) tvrdí, že čím snadněji se nám nějaká informace zpracovává, tím pravdivější a důvěryhodnější nám subjektivně připadá, a to nezávisle na jejím skutečném obsahu. Jazykový model produkuje text, který je z podstaty tréninku na lidsky psaných textech maximálně plynulý a soudržný, takže přesně tenhle mechanismus spouští u čtenáře už během prvních vět odpovědi. Soudíme kvalitu obsahu podle formy, ve které je podaný, ne podle procesu, který za ním skutečně stojí.
Český formát čísel jako riziko přesnosti
Už jsem to lehce nakousnul, ale české prostředí také hraje roli. Modely jsou trénované převážně na anglicky psaných datech – u prvních veřejných modelů jako GPT-3 tvořila angličtina podle původní studie přes 92 % tréninkových textů (Brown et al., 2020) a u Llamy 2 podle technické zprávy necelých 90 % (Touvron et al., 2023) . A víme, jak to v angličtině je, desetinná místa se oddělují tečkou a tisíce čárkou, tedy „1,234.56“. Český zápis je přesně opačný: desetinná čárka a tečka nebo mezera jako oddělovač tisíců, tedy „1.234,56“ nebo mezera a čárka „1 234,56“.
Pokud si model konvenci splete, může omylem posunout desetinnou čárku o tři řády, a u faktury nebo účetního výkazu to pak není kosmetická odchylka, ale řádový rozdíl.
Řešení? Model jako orchestrátor, ne kalkulačka
Ze všeho výše popsaného plyne jeden praktický závěr, který jsem sliboval na začátku. A vlastně je to zároveň dobrá zpráva. Model nemusí počítat sám, aby byl užitečný. Stačí, když ho přestanete považovat za kalkulačku a dáte mu roli orchestrátora. To znamená, že místo toho, aby se snažil dojít k číslu odhadem z tokenů, vygeneruje kód nebo dotaz, který výpočet provede skutečný, deterministický nástroj – Python, SQL, Excel vzorec – a teprve výsledek toho nástroje vrátí uživateli.
Tenhle přístup má i svoje jméno a solidní výzkumné zázemí. Ve strojovém učení se mu říká Program-Aided Language Models (PAL) a představili ho autoři Gao a kol. (2023). Ukázali, že když se model omezí na to, v čem je dobrý (rozklad úlohy na kroky a zápis kódu) a samotný výpočet přenechá Python interpretu, přesnost na úlohách se slovními matematickými zadáními výrazně předčí přístup, kdy model počítá „z hlavy“ krok za krokem v textu.
Rozdíl mezi těmito dvěma přístupy je v praxi otázka jedné věty v promptu, ale výsledek je zásadně jiný. Špatný přístup vypadá takto:
„Tady máš tabulku tržeb za posledních dvanáct měsíců, spočítej mi meziroční růst.“
Model se v tomhle případě pokusí odpovědět přímo z kontextu, tedy odhadem z tokenů, se všemi riziky popsanými výše. Dobrý přístup vypadá takto:
„Tady máš tabulku tržeb za posledních dvanáct měsíců. Napiš a spusť Python kód, který spočítá meziroční růst a výsledek mi ukaž i s mezivýpočty.“
Tahle jednoduchá změna přesune samotný výpočet z „hádání na základě jazykového vzoru“ na skutečný, opakovatelný a dohledatelný kód, který dá pokaždé stejný výsledek a jehož každý krok je možné zkontrolovat. Model se tak stává tím, v čem je skutečně dobrý a samotný výpočet nechává na nástroji, který je k tomu stavěný.
Většina lidí tohle rozlišení nedělá, protože rozhraní chatu vypadá stejně, ať model odpovídá z hlavy nebo generuje a spouští kód. Naučit se rozpoznat, kdy je potřeba explicitně říct „nepočítej to sám, napiš mi na to kód“, je asi nejdůležitější dovednost, kterou si z tohohle článku můžete odnést, pokud s daty pracujete pravidelně.
Jazykový model není špatný nástroj, je to jenom nesprávný nástroj na počítání přímo z hlavy. Je vynikající v porozumění kontextu, formulaci závěrů, psaní kódu a vysvětlování, ale číslo, které vám dá bez pomoci externího nástroje, je vždycky jenom odhad podaný sebejistým tónem. Jakmile tohle pochopíte, přestane vás to omezovat a začne to fungovat jako návod: nepočítejte s modelem, počítejte skrz něj.
Literatura
Alter, A. L., & Oppenheimer, D. M. (2009). Uniting the tribes of fluency to form a metacognitive nation. Personality and Social Psychology Review, 13(3), 219–235. https://doi.org/10.1177/1088868309341564
Amperity. (2026, March 24). Your data scientists were hired to build models. They’re cleaning spreadsheets instead. https://amperity.com/blog/cost-of-poor-data-quality
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. arXiv. https://arxiv.org/abs/2005.14165
Gao, L., Madaan, A., Zhou, S., Alon, U., Liu, P., Yang, Y., Callan, J., & Neubig, G. (2023). PAL: Program-aided language models. Proceedings of the 40th International Conference on Machine Learning, 202, 10764–10799. https://proceedings.mlr.press/v202/gao23f.html
Jiang, Y., Rajendran, G., Ravikumar, P., Aragam, B., & Veitch, V. (2024). On the origins of linear representations in large language models. arXiv. https://arxiv.org/abs/2403.03867
Kadlčík, M., Štefánik, M., Mickus, T., Spiegel, M., & Kuchař, J. (2025). Pre-trained language models learn remarkably accurate representations of numbers. arXiv. https://arxiv.org/abs/2506.08966
Kalai, A. T., Nachum, O., Vempala, S. S., & Zhang, E. (2025). Why language models hallucinate. arXiv. https://arxiv.org/abs/2509.04664
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12. https://aclanthology.org/2024.tacl-1.9/
QAnswer. (2026, April 3). Why LLMs are not deterministic even at temperature 0. https://www.qanswer.ai/blog/llm-non-determinism-temperature-zero
Singh, A. K., & Strouse, D. J. (2024). Tokenization counts: The impact of tokenization on arithmetic in frontier LLMs. arXiv. https://arxiv.org/abs/2402.14903
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv. https://arxiv.org/abs/2307.09288
Unstract. (2025, October 8). Why is deterministic output from LLMs nearly impossible? https://unstract.com/blog/understanding-why-deterministic-output-from-llms-is-nearly-impossible/